Brian Wallace presents tool to optimize ssDeep comparisons.
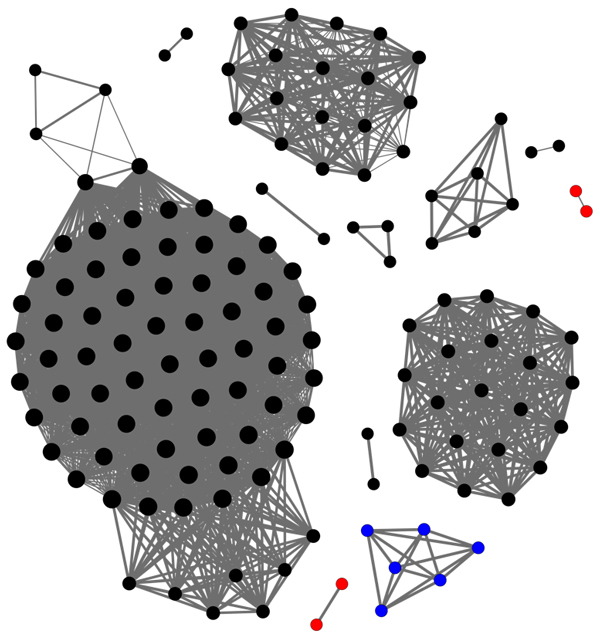
Malware rarely comes as a single file, and to avoid having to analyse each sample in a set individually, a fuzzy hashing algorithm tool like ssDeep can tell a researcher whether two files are very similar — or not similar at all.
When working with a large set of samples, the number of comparisons (which grows quadratically with the set size) may soon become extremely large though. To make this task more manageable,
Cylance
researcher Brian Wallace devised an optimization to ssDeep comparisons.
Today, we publish a
paper
in which Brian explains how this optimization works and how much it improves the performance of the comparisons to be made.
You can read the paper
here
in HTML format or
here
as a PDF.
For another way to find samples from the same family among a larger set, you may want to read the
paper
Brian published through
Virus Bulletin
in June this year, in which he looks at two .NET GUIDs that can be used for this purpose.
Posted on 27 November 2015 by
Martijn Grooten
Leave a Reply